Fault Tolerance
1) Motivazioni della progettazione Fault-Tolerance :
- Consegna prodotto nei tempi schedulati in quanto ci sono meno imprevisti
- Riduzione dell'indisponibilità, attualmente i bugs sono puramente software
- Gestione delle modifiche
- Tolleranza ai guasti indotti dall'uomo
- Sistemi distribuiti
2) Dependability (Fidatezza) :
E' l'abilità di un sistema di operare correttamente, include reliability, availability, safety, maintanability, performability, testability.
3) Reliability & Unreliability :
R(t) è la probabilità che il sistema operi correttamente nell'intervallo di tempo [0,t] ed è condizionata al corretto funzionamento al tempo 0. Unreliability F(t) = 1 - R(t) è la probabilità di fallimento in un istante qualunque nell'intervallo di tempo [0,t]. Visto che per applicazioni spaziali il tempo t è molto lungo, dell'ordine di decine di anni allora la reliability viene individuata dal numero di 9 dopo la virgola.
4) Safety :
S(t) è la probabilità che il sistema non fallisca nell'intervallo di tempo [0,t] in modo da causare danni non accettabili, ossia vi possono essere guasti ma debbono ricondurre il sistema ad uno stato sicuro.
5) Availability :
A(t) è la probabilità che il sistema sia attivo e correttamente funzionante al tempo t.
6) Graceful Degradation :
E' la capacità del sistema di diminuire progressivamente le prestazioni al fine di compensare i guasti hardware e gli errori software.
7) Maintainability :
M(t) è la probabilità che un sistema guasto venga ripristinato entro un prefissato periodo di tempo t.
8) Processo di ripristino di un guasto :
- Localizzazione del problema
- Riparazione fisica
- Riportare il sistema nelle condizioni operative
9) Fault, Error e Failure :
- Fault è il difetto fisico o malfunzionamento che avviene in qualche componente
- Error è il comportamento scorretto causato dal Fault
- Failure è l'incapacità del sistema a realizzare il suo servizio
10) Cause dei Faults :
- Errori di specifica
- Errori di implementazione
- Guasti casuali di componenti
- Disturbi esterni
11) Durata dei Faults :
- Permanente
- Transiente (una o più volte)
- Intermittente
12) Tipologie di ridondanze :
- Hardware: viene aggiunto hardware per determinare i guasti e tollerarli
- Software: viene aggiunto software per determinare i guasti e tollerarli
- Informazione: codici per rilevare e correggere errori
- Temporale: tempi extra dedicati a task volti alla fault tolerance
13) Operazioni della Fault Tolerance :
- Individuazione dell'errore
- Confinamento del danno
- Recupero dell'errore
- Trattamento del guasto
14) Tecniche di Recupero dell'errore :
- Recupero in Backward: si torna ad uno stato precedente valido, questa tecnica richiede numerosi e pianificati checkpoint
- Recupero in Forward: si cerca di arrivare ad uno stato esente da errori
15) Tecniche di trattamento dei guasti :
- Per l'errore transiente effettuare il re-boot oppure andare su di uno stato esente da errori
- Se occorre riparare il sistema può avvenire tramite riconfigurazione automatica del sistema o con riserva
16) Fault coverage :
E' una misura della capacità del sistema ad eseguire le seguenti operazioni:
- Individuazione del Fault
- Localizzazione del Fault
- Contenimento del Fault
- Recupero del Fault
17) Tipologie di ridondanze hardware :
- Passiva: tramite mascheramento viene nascosto il fault, è il caso del Voting
- Attiva: il guasto viene rilevato mediante confronto dopodichè viene eliminato mediante riconfigurazione
- Abrade: maschera il guasto sino al completamento della diagnosi dopodichè riconfigura
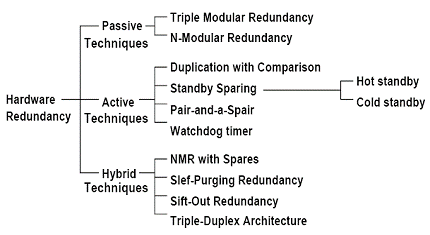
18) NMR :
E' un tipo di ridondanza hardware passiva in cui N moduli sono ridondati dopodichè il Voter fa si che la maggioranza vinca, deve ovviamente essere almeno N=3, il problema è che il Voter è un punto di failure non ridondato, si può ovviare ridondando anche esso oppure lavorando molto nel renderlo semplice ed affidabile.
Il sistema con Voter consente di mascherare sino a ![]() guasti. Un TMR (Triple Modular Redundancy ha il seguente schema:
guasti. Un TMR (Triple Modular Redundancy ha il seguente schema:
E' una forma di ridondanza statica in quanto l'interconnessione dei moduli è fissa.
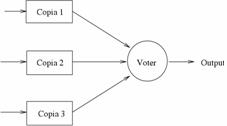
19) Ridondanza hardware attiva :
In pratica si ha una ridondanza hardware ed un blocco di confronto che determina se c'è disaccordo. Nel caso sia riscontrato un disaccordo parte una procedura per individuare il modulo guasto e per sostituirlo con una riserva la quale può essere sia fredda che calda, la ridondanza fredda necessita di un tempo non nullo per essere attivata mentre la ridondanza calda consuma energia anche se le sue funzioni non vengono utilizzate sino al momento del guasto.
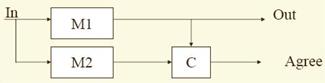
20) Ridondanza hardware ibrida :
- NMR con riserve: tramite il voting individua il modulo che ha determinato l'errore, a quel punto lo sostituisce con una delle riserve al fine di mantenere M costante
- Self-Purging NMR: tutti i moduli sono attivi, man mano che vengono identificati gli errori ed i moduli rotti essi vengono progressivamente esclusi
- Triple-Duplex: Si ha un comparatore ogni 2 moduli
21) Distanza di Hamming :
E' il numero di bit per i quali differiscono due parole binarie.
22) Criterio di parità :
- Parità pari: è un bit il cui valore è tale che il numero totale di 1 sia pari
- Parità dispari: è un bit il cui valore è tale che il numero totale di 1 sia dispari
23) Criterio di overlapped parity :
- Vengono calcolati dei check bits secondo delle regole che prendono combinazioni di opportuni bit della parola sorgente
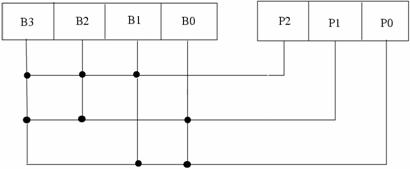
- La sindrome viene calcolata dal confronto tra i check bit ricevuti e quelli ricalcolati a partire dalla parola ricevuta, dopodichè a seconda della configurazione ottenuta viene determinato il bit errato
24) Codici m di n :
Si fa in modo che tutte le parole dell'alfabeto trasmesso abbiano almeno distanza di Hamming pari a 2 tra parole adiacenti.
25) Checksum :
- Singola precisione
- Doppia precisione
- Honeywell
- Residui
26) CRC :
Cyclic Redundancy Code, dato un messaggio lungo k bit che si vuole inviare viene creata una sequenza di frame check lunga n bit ottenuta quale resto della divisione della parola da trasmettere per il polinomio generatore. Questo frame check viene aggiunto alla parola originaria e viene a costituire la parola trasmessa. Lato ricezione si divide per il polinomio generatore e se il resto è 0 allora non ci sono stati errori, altrimenti vi sono stati e alcune occorrenze si possono anche correggere.
